

Apprentissage automatique : guide clair pour professionnels
TL;DR:
- L’apprentissage automatique est accessible à tous, pas seulement aux data scientists ou ingénieurs.
- La réussite dépend principalement de la qualité des données et de la compréhension du contexte métier.
- Les modèles tree-based sont souvent plus efficaces que le deep learning pour les données tabulaires en entreprises.
L’apprentissage automatique serait réservé aux data scientists et aux ingénieurs ? C’est l’une des idées reçues les plus répandues chez les cadres et managers. Pourtant, chaque fois que votre CRM prédit qu’un client risque de partir, que votre messagerie filtre automatiquement les spams ou qu’un outil de comptabilité détecte une anomalie dans vos factures, c’est l’apprentissage automatique qui travaille en coulisses. Vous n’avez pas besoin de savoir coder pour comprendre ces mécanismes. Vous avez besoin de savoir comment ils fonctionnent, où ils s’appliquent dans votre métier, et comment éviter les pièges courants. C’est exactement ce que cet article vous propose.
Table des matières
- Qu’est-ce que l’apprentissage automatique ?
- Comment fonctionne un modèle d’apprentissage automatique ?
- Différences et choix de modèles : tree-based, réseaux de neurones et deep learning
- Limites, risques et bonnes pratiques de l’apprentissage automatique
- Pourquoi la clé n’est pas l’algorithme mais vos données et votre contexte métier
- Aller plus loin avec l’apprentissage automatique adapté à votre secteur
- Questions fréquentes sur l’apprentissage automatique
Points Clés
| Point | Détails |
|---|---|
| Définir ses objectifs | La réussite d’un projet d’apprentissage automatique dépend d’abord d’une vision claire du problème métier à résoudre. |
| Qualité des données | Des données fiables et pertinentes sont plus déterminantes pour la performance qu’un algorithme sophistiqué. |
| Choisir le bon modèle | Les modèles tree-based dominent sur les données tabulaires, le deep learning excelle sur image et texte, il faut adapter son choix. |
| Intégrer l’humain | Impliquer l’utilisateur ou l’expert métier (HITL) permet de détecter les cas limites et de limiter les dérives. |
Qu’est-ce que l’apprentissage automatique ?
L’apprentissage automatique, souvent appelé machine learning en anglais, est une branche de l’intelligence artificielle. Pour bien situer le concept, voici comment les trois termes s’articulent :
- Intelligence artificielle (IA) : terme général désignant toute technique permettant à une machine de simuler des capacités cognitives humaines.
- Apprentissage automatique : sous-catégorie de l’IA où les algorithmes apprennent à partir de données, sans être explicitement programmés pour chaque tâche.
- Apprentissage profond (deep learning) : sous-catégorie de l’apprentissage automatique, basée sur des réseaux de neurones à plusieurs couches, particulièrement efficace sur les images, la voix et le texte.
Pour une définition simple de l’IA et de ses mécanismes fondamentaux, vous pouvez consulter notre guide complet. Ce qui distingue l’apprentissage automatique d’un logiciel classique, c’est simple : un logiciel classique suit des règles fixes écrites par un développeur. Un modèle de machine learning, lui, découvre des règles en analysant des exemples.
En entreprise, les applications concrètes sont nombreuses :
- Filtrage des emails : détection automatique des spams grâce à l’analyse de millions de messages.
- CRM prédictif : anticipation du risque de désabonnement client (churn) à partir de l’historique comportemental.
- Maintenance prédictive : détection d’anomalies dans des équipements industriels avant la panne.
- Scoring financier : évaluation automatique du risque crédit à partir de données transactionnelles.
- Recommandation de contenu : suggestion de produits ou d’articles selon les habitudes de navigation.
Une limite fondamentale mérite d’être connue dès le départ : les modèles apprennent des corrélations, pas la causalité. Un modèle peut très bien observer que les ventes de crème glacée augmentent en même temps que les noyades, sans comprendre que c’est la chaleur qui explique les deux. Cette nuance change beaucoup de choses dans la façon d’interpréter les résultats.
Conseil de pro : Avant d’adopter un outil basé sur l’apprentissage automatique, demandez à votre fournisseur quelle donnée d’entrée influence le plus les prédictions. Cette question simple révèle souvent des biais cachés.
Vous pouvez aussi explorer comment automatiser vos tâches avec l’IA pour identifier rapidement les processus de votre organisation qui se prêtent le mieux à cette technologie.
Comment fonctionne un modèle d’apprentissage automatique ?
Après avoir posé la définition, explorons concrètement le fonctionnement d’un modèle. Imaginez que vous souhaitez enseigner à un nouvel employé à distinguer les bons clients des mauvais payeurs. Vous lui montrez des centaines de dossiers passés avec leurs résultats. Il repère des schémas. C’est exactement ce que fait un modèle de machine learning.
Les étapes clés d’un projet d’apprentissage automatique sont les suivantes :
- Collecte des données : rassembler les données historiques pertinentes (transactions, comportements, mesures).
- Préparation des données : nettoyer, formater et structurer les données pour qu’elles soient exploitables.
- Choix du modèle : sélectionner le type d’algorithme adapté au problème (classification, régression, clustering).
- Entraînement : faire tourner l’algorithme sur les données pour qu’il apprenne les schémas.
- Validation : tester le modèle sur des données qu’il n’a jamais vues pour mesurer ses performances réelles.
- Déploiement et suivi : intégrer le modèle dans les outils métier et surveiller ses performances dans le temps.
Voici un tableau récapitulatif pour visualiser chaque étape :
| Étape | Action principale | Point de vigilance |
|---|---|---|
| Collecte | Identifier les sources de données | Pertinence et exhaustivité |
| Préparation | Nettoyer et structurer | Valeurs manquantes, doublons |
| Choix du modèle | Sélectionner l’algorithme | Complexité vs interprétabilité |
| Entraînement | Ajuster les paramètres | Surapprentissage (overfitting) |
| Validation | Tester sur données réelles | Représentativité du jeu de test |
| Déploiement | Intégrer et surveiller | Dérive du modèle dans le temps |
Un point souvent sous-estimé : la qualité du modèle dépend avant tout de la qualité des données. Les modèles nécessitent de grandes quantités de données fiables pour produire des résultats exploitables. Un algorithme sophistiqué nourri de données médiocres donnera des prédictions médiocres. L’inverse est rarement vrai.

Pour choisir les bons outils IA en entreprise, il est utile de comprendre ces étapes avant de comparer les solutions du marché.
Conseil de pro : Validez toujours votre modèle sur des données récentes et représentatives de votre contexte réel, pas uniquement sur les données d’entraînement. Un modèle performant en laboratoire peut échouer sur le terrain.
Différences et choix de modèles : tree-based, réseaux de neurones et deep learning
Une fois le fonctionnement compris, il faut distinguer les modèles en fonction de leurs forces et de leurs limites. Tous les algorithmes ne se valent pas selon le contexte.
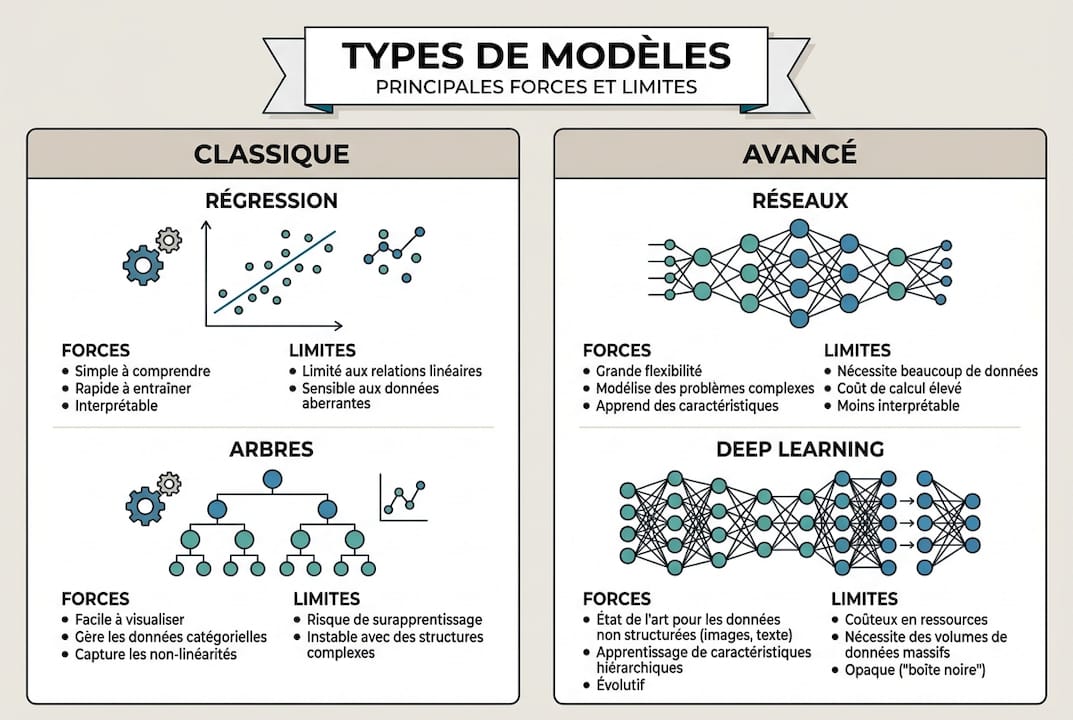
Voici un tableau comparatif des grandes familles de modèles :
| Type de modèle | Forces | Limites | Cas d’usage typique |
|---|---|---|---|
| Régression linéaire/logistique | Simple, rapide, interprétable | Peu adapté aux relations complexes | Scoring, prévisions simples |
| Arbres de décision / XGBoost | Robuste sur données tabulaires, interprétable | Moins efficace sur images/texte | Finance, RH, marketing |
| Réseaux de neurones | Capture des relations complexes | Nécessite beaucoup de données | Prévisions avancées |
| Deep learning | Excellent sur image, voix, texte | Coûteux, boîte noire | Vision, NLP, audio |
Une idée reçue très répandue est que le deep learning est toujours supérieur. Les données empiriques racontent une autre histoire. Sur des données tabulaires classiques (tableaux Excel, bases CRM, données financières), les modèles tree-based surpassent souvent les réseaux de neurones profonds. Une étude de référence confirme que XGBoost gagne sur 68 jeux de données tabulaires face au deep learning.
En pratique, voici comment choisir votre type de modèle :
- Volume de données faible ou moyen : privilégiez les arbres de décision ou la régression.
- Données sous forme de tableau : XGBoost ou Random Forest sont souvent le meilleur point de départ.
- Images, voix ou texte non structuré : le deep learning devient pertinent.
- Besoin d’interprétabilité forte (audit, conformité) : évitez les boîtes noires, préférez les modèles explicables.
- Rapidité de mise en production : les modèles simples déploient plus vite et coûtent moins cher à maintenir.
Pour comparer les solutions disponibles en 2026, notre comparatif IA 2026 vous donnera une vue d’ensemble actualisée des outils du marché.
Limites, risques et bonnes pratiques de l’apprentissage automatique
Comprendre les possibilités, c’est aussi reconnaître les défis concrets de l’apprentissage automatique en entreprise. Les échecs ne manquent pas, et ils suivent souvent les mêmes schémas.
Les défaillances les plus fréquentes incluent :
- Distribution shift : le modèle est entraîné sur des données passées, mais le monde change. Un modèle de scoring crédit entraîné avant une crise économique peut devenir obsolète en quelques mois.
- Biais amplifiés : si vos données historiques reflètent des biais humains (discrimination à l’embauche, par exemple), le modèle les reproduit et les amplifie.
- Hallucinations : certains modèles génèrent des réponses plausibles mais fausses, sans signal d’alerte.
- Cas limites (edge cases) : les situations rares ou inhabituelles sont souvent mal gérées.
Les défaillances sur distribution shift et les biais amplifiés sont parmi les causes les plus documentées d’échecs en production.
Un modèle de machine learning ne raisonne pas. Il reconnaît des schémas. Dès que la réalité s’éloigne de ses données d’entraînement, ses prédictions se dégradent, souvent sans signal d’alerte visible.
Pour sécuriser une intégration, les bonnes pratiques recommandées incluent l’approche HITL (Human In The Loop) : impliquer l’humain pour les edge cases critiques, avant de laisser le modèle décider seul. Il faut aussi construire des benchmarks personnalisés sur vos propres données, pas seulement sur des jeux de données génériques.
Protéger la confidentialité des données est également non négociable. Avant de transmettre des données clients ou financières à un outil externe, vérifiez les conditions de traitement et la conformité RGPD.
Pour réussir votre démarche, consultez nos guides sur intégrer l’IA dans l’entreprise et les enjeux IA professionnels en 2026.
Pourquoi la clé n’est pas l’algorithme mais vos données et votre contexte métier
Après avoir exploré limites et bonnes pratiques, il est utile de prendre de la hauteur sur ce qui fait vraiment le succès de l’apprentissage automatique. Chez OMRI, nous observons une tendance récurrente : les organisations cherchent d’abord le meilleur modèle, le plus récent, le plus médiatisé. C’est une erreur de priorité.
La vraie différence entre un projet qui réussit et un projet qui échoue ne tient presque jamais à l’algorithme choisi. Elle tient à la clarté de la problématique métier, à la qualité des données disponibles et à la capacité de l’équipe à interpréter les résultats avec du recul.
Sans une question précise à laquelle répondre, même le modèle le plus sophistiqué reste une boîte noire inutile. Les organisations qui progressent vraiment investissent dans la gouvernance de leurs données et dans la formation de leurs équipes aux méthodes, pas seulement dans la technologie. Découvrez comment OMRI accompagne les entreprises dans cette démarche structurée et pragmatique.
Aller plus loin avec l’apprentissage automatique adapté à votre secteur
Passer de la compréhension à l’action, c’est souvent là que le chemin se complique. Les concepts sont clairs, mais comment les appliquer à votre secteur, vos données, vos contraintes réelles ? C’est précisément pour cela qu’OMRI a conçu ses programmes de formation.
Que vous souhaitiez maîtriser les bases de la formation en IA générative ou structurer une stratégie d’accompagnement IA en entreprise, OMRI propose des parcours adaptés aux professionnels actifs. Pas de jargon inutile, pas de théorie déconnectée du terrain. Pour commencer, notre guide complet IA vous offre une base solide avant de choisir votre programme.
Questions fréquentes sur l’apprentissage automatique
Quelle est la principale différence entre apprentissage automatique et intelligence artificielle ?
L’intelligence artificielle désigne toute technique visant à simuler l’intelligence humaine, tandis que l’apprentissage automatique est une sous-catégorie focalisée sur les algorithmes capables d’apprendre à partir des données. L’un est le domaine, l’autre est une méthode parmi d’autres au sein de ce domaine.
Quels types de tâches professionnelles profitent le plus de l’apprentissage automatique ?
Les domaines qui manipulent de gros volumes de données répétitives ou cherchent à automatiser des prises de décision tirent le plus de bénéfices, comme le marketing, la finance ou la maintenance prédictive. Plus vos données sont structurées et abondantes, plus le potentiel est élevé.
Doit-on privilégier les modèles deep learning à chaque fois ?
Non, sur des données tabulaires classiques en entreprise, les modèles à base d’arbres type XGBoost sont souvent plus robustes, rapides et interprétables que les réseaux neuronaux profonds. Le deep learning brille surtout sur les images, la voix et le texte non structuré.
Quels sont les principaux pièges à éviter quand on intègre du machine learning ?
Il faut éviter de négliger la qualité des données, sous-estimer les cas limites et biais amplifiés et croire que le modèle fournit une interprétation causale et infaillible. Un suivi humain régulier reste indispensable, surtout dans les premières semaines de déploiement.

